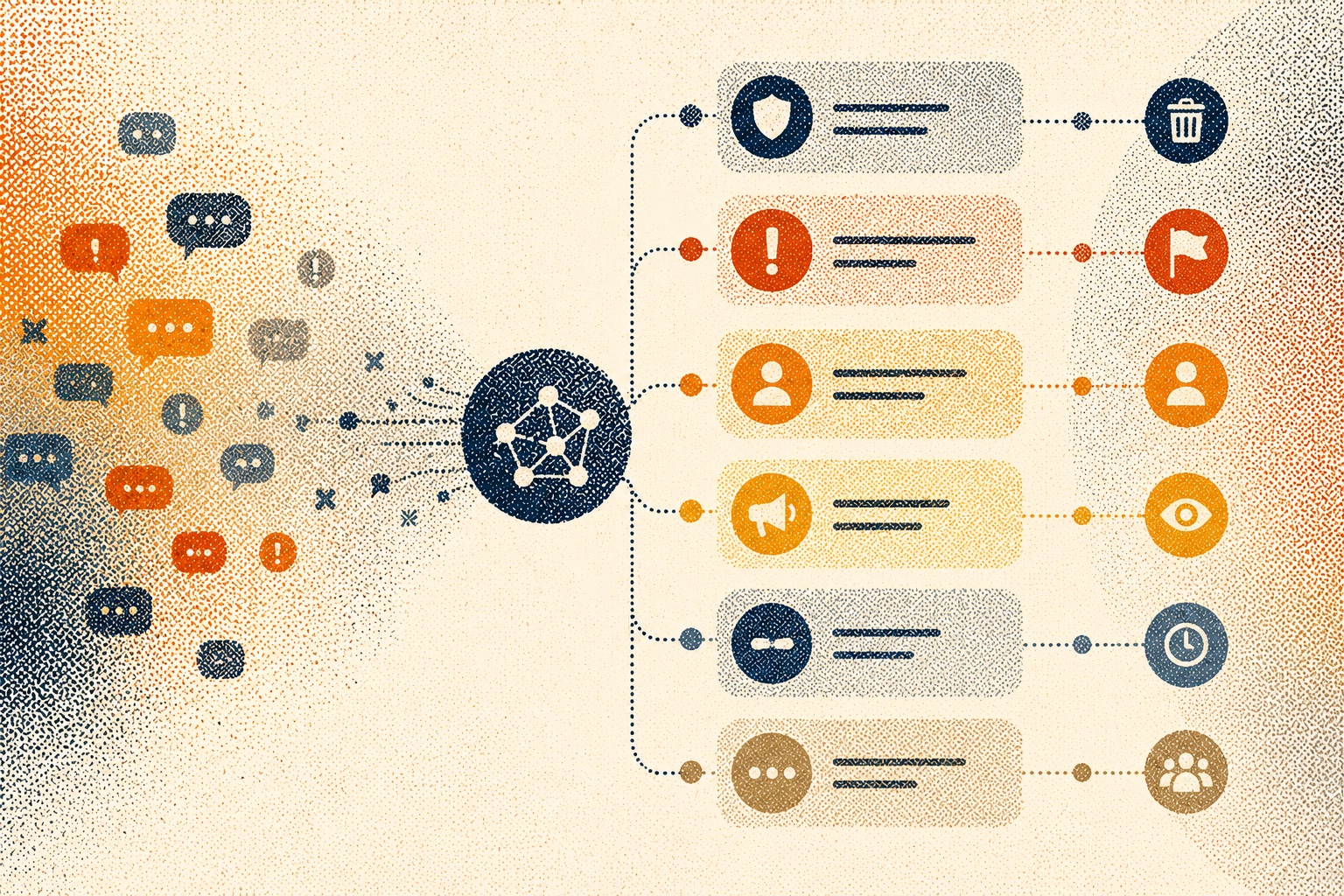
A customer-defined classification taxonomy is a structured framework of content categories, severity tiers, and contextual rules that reflects your own moderation policy, not a universal toxicity standard. It tells an automated system exactly what you consider a violation, at what severity, and what action to take.
Why generic toxicity scores fall short for publishers
News publishers, sports organisations, and broadcasters each have distinct community standards. A sports league's comment policy looks very different from a national newspaper's, and neither looks like the default output of a general-purpose toxicity model.
Tools like Perspective API assign a probability score based on a fixed model trained on broad data. They have no knowledge of your editorial policy, your audience, or the specific language patterns in your comment sections. With Perspective API's retirement, publishers relying on it face an urgent need to move to more policy-aligned solutions. Rules-based keyword filters have the opposite problem: they match strings, not meaning, and break immediately when language evolves. New slang, coded phrases, or deliberate misspellings can bypass them entirely. The rapid development of AI/ML-based computational models for toxicity prediction reflects exactly this demand for more accurate, context-aware assessment beyond what blunt keyword matching can achieve.
The result is a double failure. Legitimate debate gets flagged as harmful (false positives), and genuine violations in novel language slip through undetected (false negatives). Almost 50 million moderation decisions on major platforms were reversed in just two years under the European Digital Services Act, which gives you a sense of how consequential mis-classification is at scale.
Consider a concrete example: a publisher may have a clear rule that profanity is not permitted. At high comment volume, that rule becomes unenforceable without a system that understands what counts as profanity in context, across platforms, in real time. A generic model cannot make that call reliably. A custom moderation taxonomy can.
The components of a customer-defined classification taxonomy
A well-built taxonomy has five components. Each one does a specific job. Together, they turn a policy document into an operational system.
1. Categories
Categories are the top-level content types the taxonomy recognises: hate speech, harassment, misinformation, spam, off-topic content, profanity, threats. The key requirement is that categories map directly to your published community guidelines, not to a vendor's default labels. Each category needs a plain-language definition that a human moderator and a machine classifier can both apply consistently. If a moderator cannot apply the definition reliably, a classifier cannot learn it. The scale of the challenge is significant: Meta removed 27.2 million pieces of hate speech violating content from Facebook in Q1 2023 alone, which illustrates why precise, policy-specific category definitions matter so much at volume.
2. Severity tiers
Not all violations warrant the same response. A tier structure, for example low, medium, high, and critical, determines the automated action taken. Low severity might trigger a flag for human review. High severity triggers immediate removal. Tiers are what make the taxonomy actionable at scale rather than just descriptive.
3. Contextual modifiers
Rules that shift classification based on surrounding context. The subject of a comment matters: criticism directed at a public figure in their professional capacity is different from a personal attack on a private individual. The platform matters. The post topic matters. Contextual modifiers are what separate a classification taxonomy from a keyword list. They encode the judgement calls that experienced moderators make instinctively.
4. Edge-case rules
Every policy has grey areas. Edge-case rules document how specific ambiguous situations should be resolved. These are often the most valuable part of the taxonomy because they capture institutional knowledge from your moderation team that never makes it into a formal policy document. Running structured sessions with your moderators to surface recurring edge cases is one of the most productive things you can do when building a taxonomy.
5. Escalation paths
For content that automated classification cannot resolve alone, the taxonomy defines who reviews it, on what timeline, and what the fallback action is while it awaits review. Escalation paths keep the system from stalling on genuinely ambiguous content without defaulting to either removing everything or leaving it up.
How it differs from generic toxicity classifiers and keyword filters
vs. generic toxicity classifiers (e.g. Perspective API, Hive)
Generic classifiers output a probability score against a fixed model. They produce high false-positive rates on legitimate debate such as political argument or sports banter, and they miss violations expressed in community-specific slang or coded language. Understanding how to identify hate speech, scams, and toxic comments before they cause damage requires exactly the kind of contextual precision that generic models lack. A study involving 1,854 human participants found that larger and more advanced multimodal large language models can produce context-sensitive hate speech evaluations closely aligned with human judgment, yet demographic and lexical biases still persisted, especially in smaller models. That finding supports the case for baking context into classification from the start rather than treating it as a post-processing step. A customer-defined taxonomy does exactly that.
vs. rules-based keyword filtering
Keyword filters match strings. They cannot distinguish intent, tone, or context. They require constant manual maintenance as language evolves, and they fail silently when new slang or coded language emerges. A classification taxonomy for comment moderation captures meaning, not just characters. That distinction matters enormously at volume.
Content strategy fundamentals: getting your taxonomy right before you build
A taxonomy is only as strong as the content strategy thinking behind it. Before writing a single category definition, it is worth establishing three things: what your community exists to do, what kinds of conversation you want to encourage, and where your moderation policy genuinely differs from platform defaults. These are content strategy questions, not technical ones, and they determine whether your taxonomy produces a well-organised, discoverable comment environment or simply a filtered one.
Getting this right also means thinking about how your moderation categories map to your broader editorial goals. A publisher whose strategy centres on constructive reader debate will structure categories differently from a broadcaster whose community is primarily reactive. Your taxonomy should reflect that intent, not just your list of prohibited content. This is what separates a taxonomy built on content strategy fundamentals from one built purely on legal minimums.
Building a customer-defined classification taxonomy: a practical process
This is the part most teams underestimate. The taxonomy is not a technical artefact. It is a policy artefact that gets translated into something a classifier can use. Here is a practical sequence for doing that.
Step 1: Audit your existing editorial policy
Start with your published community guidelines. Map every stated rule to a candidate category. Identify gaps where the guidelines are vague or where moderators currently make inconsistent calls. Inconsistency in human moderation is a signal that the policy definition needs work before it can be taught to a system.
Step 2: Interview your moderation team
Your moderators hold institutional knowledge that no policy document captures. Run structured sessions to surface the edge cases they encounter repeatedly. Ask them where they feel uncertain, where they disagree with each other, and what types of content they find hardest to call. These become your edge-case rules.
Step 3: Translate policy into machine-readable categories
For each category, write a definition specific enough to be applied consistently. Avoid circular definitions. Ground each definition in observable characteristics of the content: what is present, what is absent, who is targeted, in what context. Simplicity is a feature here, not a shortcut.
Step 4: Assign severity tiers and actions
For each category, define the severity tier and the automated action that follows. This is where the taxonomy becomes operational rather than theoretical. A category without an assigned action is just a label.
Step 5: Map edge cases and contextual modifiers
Document the grey areas explicitly. Define how context, such as subject type, platform, or post topic, shifts classification. The more precisely you map these, the fewer escalations you will generate and the more consistent your automated decisions will be.
Step 6: Validate against historical content
Run your taxonomy against a labelled sample of historical comments. Check for false positives and false negatives. Revise definitions where the taxonomy produces unexpected results. This step often surfaces ambiguities in the definitions that seemed clear in the abstract.
Content organisation and discoverability: structuring your taxonomy so it can be used
A taxonomy that exists only in a shared document is not an operational system. For it to function across moderation teams, editorial stakeholders, and technical integrations, it needs to be organised and discoverable in practice.
Structure your categories hierarchically: top-level types (harassment, misinformation, spam) with sub-categories beneath them (targeted harassment, coordinated harassment, self-harm encouragement). This makes it easier for moderators to locate the right definition quickly and for classifiers to handle overlapping signals without ambiguity. Each category definition should sit in a single canonical location, with clear version history so that any change is traceable.
Discoverability matters for onboarding too. New moderators should be able to find the definition for any category within seconds, understand its severity tier, and know what action it triggers. If that is not achievable with your current taxonomy structure, reorganise it before you try to train a classifier on it. A well-organised taxonomy reduces training time, reduces moderation inconsistency, and reduces the cost of updates when policy changes.
Worked example: criticism vs. harassment of public figures
A national news publisher has a guideline that reads: "Criticism of public figures in their professional capacity is permitted. Personal harassment is not." This is a common and sensible rule. The challenge is operationalising it.
Take two comments. The first: "The minister's economic policy is a disaster and she should resign." The second: "The minister is a worthless human being who should disappear." A generic classifier may assign similar toxicity scores to both. Both contain strong negative language directed at a named individual. The model has no way to distinguish professional criticism from personal attack.
A custom comment classification taxonomy handles this differently. It defines two categories with distinct criteria. "Policy criticism" applies when negative content targets a person's professional decisions, public statements, or official conduct. "Personal harassment" applies when negative content targets a person's identity, character, or personal life without reference to their public role. The contextual modifier "subject is a public figure acting in official capacity" shifts the classification toward the permitted category.
The classifier learns this distinction from the publisher's own moderation history. The first comment passes. The second is flagged and removed. No human moderator needed to review either. That is the practical value of a well-structured taxonomy.
Customer journey optimisation: moderation as a reader experience decision
Comment moderation is not just a safety function. It is a reader experience decision that shapes how people move through your content and whether they return.
A reader who encounters harassment in a comment thread below an article they value does not usually report it. They leave. A reader who finds that debate is consistently civil and on-topic is more likely to contribute, share, and return. Research into AI-assisted comment moderation at The New York Times found that adopting AI moderation led to an increase in articles with comment sections and heightened engagement among prolific commenters, without compromising the overall quality of published comments. That is the customer journey dimension that moderation taxonomy design often ignores: the taxonomy you build determines the environment your readers experience, which determines their behaviour downstream.
This has practical implications for how you design your categories. It is worth mapping the reader journey through your community and identifying the points where comment quality most directly affects engagement, subscription conversion, or time on site. For a news publisher, that might be comment threads on breaking news, where reader emotion runs highest. For a broadcaster, it might be live event threads. Prioritise your taxonomy's precision in those areas. The categories you build to protect those touchpoints will have the highest impact on the reader outcomes that matter to your business.
Business alignment and measurement: making moderation performance visible
A customer-defined taxonomy makes moderation measurable in ways that generic tools do not. Because every classification decision maps to a specific category, severity tier, and action defined by your own policy, you can report on performance in terms your business actually understands.
Rather than reporting a toxicity score, you can report: how many harassment violations were detected and actioned this week, how that breaks down by severity tier, which categories are generating the most escalations, and where false-positive rates are highest. These are metrics that editorial leadership, legal teams, and trust-and-safety functions can all engage with meaningfully.
This also enables alignment across business functions. Editorial can see whether moderation decisions reflect their policy intent. Legal can track category-level trends relevant to regulatory obligations under frameworks like the Digital Services Act. For Australian news publishers, the Voller verdict's implications for publisher liability make category-level tracking of user comments a practical legal necessity. Product teams can use category-level data to understand which content types are driving the most community friction and factor that into decisions about comment placement, thread structure, or audience access. Moderation stops being a cost centre with opaque outputs and becomes a source of structured data that informs decisions across the organisation.
Build this measurement layer in from the start. Define the metrics you will track, the reporting cadence, and who owns each metric before you go live. A taxonomy built for accountability produces accountability. One built only to classify does not.
Maintaining the taxonomy as policy and language evolve
A taxonomy is not a set-and-forget artefact. Two things drive the need for ongoing updates.
Policy changes. Editorial policy shifts in response to external events: a federal election, a high-profile incident on your platform, or regulatory change. The European Digital Services Act is a clear example of how regulatory pressure forces publishers to revisit and formalise their content moderation policies at pace. When policy changes, the taxonomy must change with it. Build a review cadence into your moderation operations, not just a reactive process triggered by incidents.
Language evolution. Social media language moves fast. Slang terms, coded language, and new forms of harassment emerge continuously. A taxonomy that is not updated develops blind spots. The best taxonomies are connected to live moderation decisions, so new patterns surface quickly and can be incorporated into category definitions before they become a significant enforcement gap.
Treat the taxonomy as a living document. Teams that review and update it regularly maintain accuracy. Teams that treat it as finished see performance degrade over time, often without noticing until the false-negative rate has already climbed.
Where a customer-defined taxonomy fits in your moderation architecture
The taxonomy is the policy layer. It defines what counts as a violation. The classifier is the execution layer. It applies the taxonomy to incoming content at scale. The audit trail is the accountability layer: every classification decision should be traceable back to the taxonomy rule that triggered it. Human review sits above automated classification for escalations and genuine edge cases, not as the primary workflow.
Platform-native moderation tools on Facebook, Instagram, and YouTube do not support customer-defined classification taxonomies. They apply platform-level rules, not publisher-specific editorial policy. For publishers operating across multiple platforms at high comment volume, that gap is significant. Your community guidelines are not the same as Facebook's community standards, and your automated moderation should reflect that.
Putting it into practice
A customer-defined classification taxonomy is the mechanism that makes your community guidelines enforceable at scale. Without one, you have a policy document. With one, you have an operational system that can act consistently on thousands of comments per minute without losing the nuance your editorial team built into the policy.
Building and maintaining one takes investment. Generic models that do not know your policy, or keyword filters that break when language shifts, are more expensive in the long run. Mis-classification at scale has real consequences: for your community, for your brand, and increasingly for your regulatory obligations.
Sence's Community-Builder is built around exactly this concept. Every classifier Sence builds starts from the customer's own taxonomy, with no default toxicity model applied. Only what your organisation has trained the system to recognise.



.png)