Smarter Moderation. Stronger Engagement.
In a world of noise, Sence helps you hear what matters.
A platform to protect, understand, and grow your brand's community.

In a world of noise, Sence helps you hear what matters.
A platform to protect, understand, and grow your brand's community.


.png)

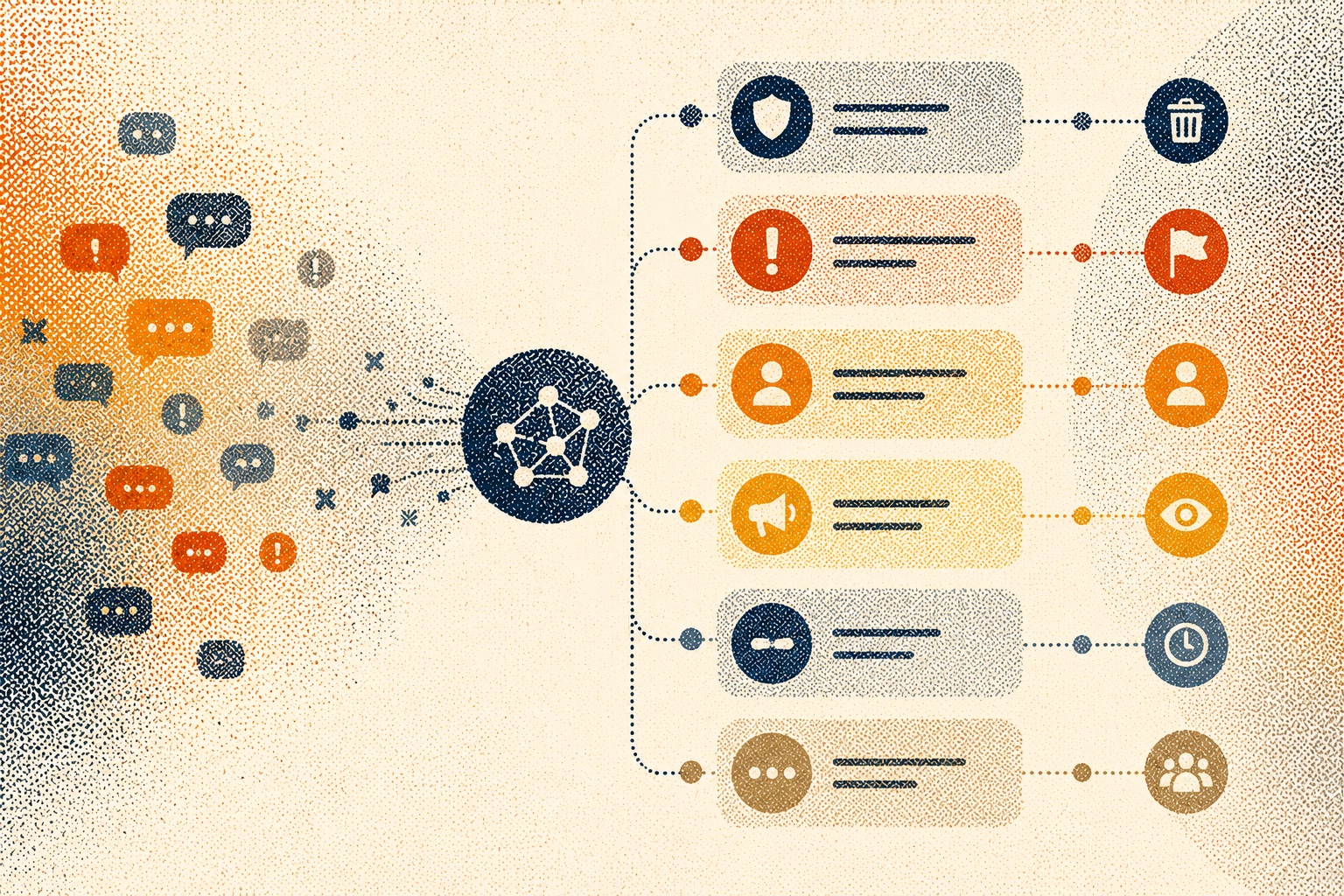
Automatically remove abuse, spam, scams and harmful content in real time, while keeping comment sections open and algorithm-friendly.
Surface high-intent comments and super advocates, deploy on-brand smart replies and respond at scale without increasing headcount.
Dynamic thematics and brand-calibrated sentiment reveal what content drives engagement, what sparks backlash and where customer intent is emerging.
Seamlessly integrate Sence with your existing social platforms and marketing tools, or build custom integrations to empower your team with unified insights.

We take a bespoke, enterprise partnership approach, conducting dedicated workshops to deeply understand your brand strategy and tone of voice. Once deployed, our AI continuously learns and improves with every interaction.
Absolutely. Sence integrates smoothly with major digital and social-media platforms as well as custom enterprise marketing tools, ensuring frictionless workflow adoption. Additionally, custom integrations tailored exactly to your organizational needs are available.
Yes, Sence offers full historical conversation analysis. Access, analyze, and benchmark conversation shifts and trends over any period. Quickly reference past performance, inform future strategies, and compare brand perception over weeks, months, or even years, empowering your decisions with historical context.
Sence uniquely blends sophisticated AI Conversational Intelligence, deep brand customization, and predictive analytics. Not just sentiment tracking, we precisely translate millions of online conversations into strategic, actionable insights aligned directly to your enterprise objectives.
Insights are delivered instantly. Whether it's an event, campaign, or emerging trend, you get real-time community sentiment, trending topics, influencers, and predictive insights right away. That way, you never lose critical time or competitive advantage.


























.png)














.png)